この記事は個人的な理解を多分に含んでいるため、間違っている情報も含まれているかもしれません。ご了承ください。また有識者の方が見ていれば修正コメントをいただけると幸いです。
コンテナとDocker
k8sを知るうえでまずDockerについて知らなければいけません。Dockerは主題ではないので軽く必要な部分だけを説明していこうと思います。
VM仮想化とコンテナ仮想化
「仮想サーバ」「仮想マシン」というのは、
ハードウェアに搭載されているプロセッサやメモリの使用時間を細かく分割しそれぞれをひとまとめにし複数の独立したサーバのように機能させ作られたサーバのことです。
仮想サーバの利点はあるOS上に別のOSのVMを立てられることにあります。WindowsOS上にLinuxOSを立てるといったことが可能です。
それに対し、
1つのOS上に「コンテナ」と呼ばれる「他のユーザから隔離されたアプリケーション実行環境」を作り、あたかも独立したサーバのように使おうというのが「コンテナ仮想化」です。
仮想サーバに比べリソース消費が少なく同じHWであれば仮想化―バより多くの実行環境を用意できます。
(Dockerが注目される理由はここではなく、DevOpsという開発手法との関わりから来ています)

なぜコンテナが必要なのか
コンテナ、というかDockerの利点は、
- ポータブルである
- どんな環境でも(開発、テスト、本番環境)全く同じ環境で実行可能である
- アプリケーションがパッケージ化されることによる開発時間の短縮
- 継続的インテグレーション/デリバリー(CI/CD) ⇒ DevOps
- 複製が容易(単一ファイルのコピー)
- マイクロサービス化の促進
- コンテナ単位のデバッグ
などがあげられます。
Docker基礎
よく使うコマンドはこの4つ程度です。
- docker run
- コンテナを実行する
- docker images (image lsでも代用可)
- コンテナイメージの一覧を見る
- docker ps
- 実行中のコンテナ一覧を見る
- -aオプションで停止中のコンテナも見える
- docker build
- Dockerfileの定義に基づいてコンテナイメージをビルドする
Dockerの詳しい使い方?というか基礎コマンドの使い方は以前このブログでも紹介したのでそれを参照してくてみてください。
ken-memo.hatenablog.com
ここで説明していないものとしてDockerfileがあります。
dockerはコマンド1行でコンテナイメージを作成できますが、長くなる時や何度も作るときはDockerfileという定義ファイルを用意してdocker buildコマンドで実行しコンテナイメージを作成する方法があります。
Dockerfileを使うことで公開されているimageに自分独自の環境設定を加えることができます。
以下Dockerfileの例です。
FROM golang:latest as builder WORKDIR /app COPY go.mod main.go ./ RUN CGO_ENABLE=0 GOOS=linux go build -a -installsuffix cgo -o main . FROM alpine:latest RUN apk --no-cache add ca-certificates WORKDIR /root/ COPY --from=builder /app/mail . EXPOSE 8080:80 CMD ["./main"]
ここにDockerfileの各定義の詳細が書いてあります。
Dockerfileによるビルド
以下はFROMを二つ使ったマルチステージビルドの方法が書いてあります。
Dockerのマルチステージビルドを使う
Kubernetes基礎とアーキテクチャ
それでは本題に入っていきます。
クラスタ, Node, Pod
k8sはクラスタと呼ばれる構成単位からなります。クラスタは一つ以上のマスターノードと一つ以上のワーカーノードからなります。
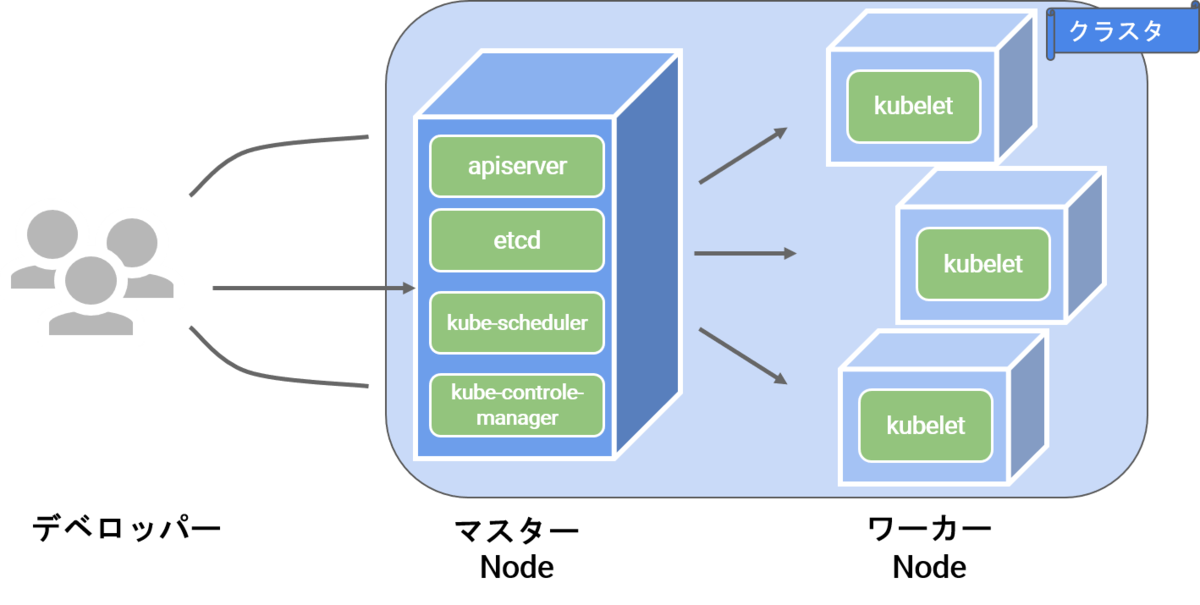
我々はまずマスターノードのapi-serverへアクセスし、ワーカーノードの監視や管理をマスターノードが行います。
マスターノードは大きく分けて以下の4つのコンポーネントから構成されます。
- kube-api-server
- すべての操作は
kubectlコマンドによってapi-serverを介して行われる
- すべての操作は
- etcd
- k8sのデータストア
- kube-control-manager
- 各コントローラー(Deployment, Service, Cronjob...)を管理実行
- kube-scheduler
- どのサーバにどのコンテナを入れるかなどを管理します。 (Cassandraなどの重いアプリは高負荷にも耐えられるサーバへ配置するなどの処理を行ってくれます)
GKEではマスターノードを作業者が操作することは基本的にありませんので特に意識する必要はないと思います。(私自身よくわかっていません。)
各ワーカーノードにはkubeletと呼ばれる管理コンポーネントが存在します。 kubeletはPod(≒コンテナ)とapi-serverを繋いで、リソースの管理を行います。
Pod
k8sはPodと呼ばれる最小単位で構成されています。
Podは常にワーカーノード上で動作します。ノードは複数のPodを持つことができ各Podはkubeletによって管理されています。
Podは先ほど"≒コンテナ"と表しましたが、具体的には、複数のコンテナを含むことができ以下のものを含みます。

また同じような機能を持ったPodはServiceという論理セットにまとめられ管理されます。 Podは停止を想定して設計されますが、DeploymentというAPIリソースによって同じサービスのPodが最低何台立ち上がっているかを監視しています。 Serviceの中でPodが1台停止した場合、Deploymentはすぐに1台を複製してくれます。 (ServiceとDeploymentについては後述します)

k8sにおけるスケールは基本的にPod単位で行われます。
仮にWordPressのサーバを立てるとして、
①Pod1つに、Webサーバ・DBサーバを入れる
②PodAにWebサーバ、PodBにDBサーバ
という2つのデザインがあると思います。
この場合どちらで構成するかは時と場合によります。
先ほどスケールはPod単位といいましたが、①をスケールする場合DBもスケールされてしまいます。各Webサーバが別々のDBを参照してしまいます。これでは良くないですよね?なのでスケールが想定されている場合は、②のような構成にして、スケールする際はPodA(webサーバ)のみをスケールするようにします。
kubectl コマンド
先ほど少し取り上げましたがk8sは基本的にkubectl(きゅーぶこんとろーる)コマンドですべてを行います。よく使われるコマンドについて説明していきます。
まず、Podの作成について、k8sではマニフェストファイルというファイルを用いてPodの作成を行います。Serviceなどの作成でも用います。(Dockerfileみたいな感じです) このマニフェストファイルはYAMLで記述します。 テンプレートは以下のような感じです
apiVersion: v1
kind: Pod
metadata:
name: pod-name
labels:
key: value
spec:
containers:
- name: container-name
image: container-image
上から説明していきます。
"apiVersion": 下記を参照してください。
Kubernetesの apiVersion に何を書けばいいか
kind: Pod, Service, Deploymentなどのリソースを記載します。
metadata.name: そのkindの名前を定義します。
metadata.labels: Podの場合ラベルを記載します。Serviceを立てる際はこのラベルとServiceのマニフェストファイルに記述するセレクタと呼ばれる属性とを対応させます。
spec.container: 名前と使用するコンテナイメージを記載します。imageにはalpine:latestなどと記載します。
ちなみにalpineOSとはコンテナ用に開発されたOSでとても軽量に出来ています。コンテナでは軽量=高速と考えて頂いてOKです。 (イメージサイズはCentOSが240MB程度に対してalpineOSは5MB程度)
マニフェストファイルを用いてPodを作成する
$ kubectl apply -f basic-pod.yaml
起動中のPodを一覧表示
$ kubectl get pods または、 $ kubectl get po
Podのラベルで検索することもできます。
$ kubectl get pods -l app=web
kubectl getコマンドでは-o wideを付けることでより詳細な情報を得ることができます。
起動中のPodのログイン
$ kubectl exec -it <Pod名> <実行コマンド>
Dockerでも出てきたこのexecコマンドは実行名のところをbashとしてよく用いられますが、書いてある通り実行コマンドなのでlsなどのコマンドで表示だけさせることも可能です。
(bashを実行することでログインと等価になっている)
起動中のPodの定義を変更
マニフェストファイルで作ったPodの定義を少しいじりたいときは、停止→変更→起動ではなく直接いじることも可能です。
$ kubectl edit pods <Pod名>
API リソースを一覧表示
ここまでPodに関する操作のみを扱ってきましたが、k8sにはもっとたくさんのリソースがあります。どんなリソースがあるのか見たいときは以下のコマンドを打ってみましょう。
$ kubectl api-resources
ServiceやDeploymentなどと言ったapi-resourceが一覧表示されます。
kubectl get podsをkubectl get poと表記しましたが、この略称も出てきます。
マニフェストファイルの定義を調べる
$ kubectl explain Pod $ kubectl explain Pod.spec
APIリソースの定義に何があるか忘れてしまったときは上記のコマンドで調べることができます。
Podをネットワークに公開するService
Serviceがどういうものか少し上でも説明しましたが、PodのIPアドレスを作業者が意識せずに単一のエンドポイントで通信する方法です。
通信というのは、 Pod⇔Pod、作業者⇔Pod の2種類がありますが、それぞれにServiceのタイプが違います。
ClusterIP(Pod⇔Pod)
クラスタ内のIPにServiceを公開します。ClusterIPではPodからのみ別のPodにアクセスすることができます。

NodePort (Pod⇔作業者またはインターネット)
各NodeのIPで、NodePort上でServiceを公開します。また、そのServiceが転送する先のClusterIPが自動的に作成されます。

LoadBalancer
Serviceを外部に公開したい(外部IPを割り当てる)場合はLoadBalancerをServiceのtypeをLoadBalancerにします。
NodePortではClusterIPを自動的に作成してくれましたが、LoadBalancerはNodePortとClusterIP両方を作成してくれます。
もちろん本来のロードバランサの機能(ネットワーク経由でのタスクの割り当てを、複数のバックエンドサーバーに分散させるロードバランシング)も持っています。
※ここで作成されるロードバランサは基本的にL4ロードバランサです。

ラベルとセレクタ
PodとServiceを対応させるために、Podにラベル、Serviceにセレクタを記述します。 以下はマニフェストファイルの例です。
# Podのマニフェストファイル apiVersion: v1 kind: Pod metadata: name: nginx labels: app: web #これがラベル spec: containers: - name: nginx image: nginx:stable-alpine
#Serviceのマニフェストファイル apiVersion: v1 kind: Service metadata: name: nginx-nodeport spec: selector: app: web #これがセレクタ type: NodePort # このマニフェストファイルはNodePortのもの ports: - port: 80 targetPort: 80 nodePort: 30001
コンテナの監視
k8sが行うコンテナの監視は2種類あります。
Podを作成する際にマニフェストファイルに記述します。
spec.containers.readinessProbe
spec.containers.livenessProbe
readinessProbe
- そのコンテナにトラフィックを流しても良いかどうか判断する
livenessProbe
- そのコンテナを再起動すべきかどうか判断する
コンテナ(というかプロセス)は落ちるもの(らしい) その落ちたプロセスを監視して自動復旧してくれるからk8sはすごいんです。
ただこれらのProbeには何も設定されていません。作業者が自分で設定します。 以下のような設定項目があります。
- initialDelaySeconds
- コンテナ起動後からProbeを最初に実行するまでの時間(秒)
- periodSeconds
- Probeを実行する間隔
- failureThreshold
- 失敗と見做すProbeの結果回数
- successThreshold
- 成功と見做すProbeの結果回数
- timeoutSeconds
- Probeの実行時間猶予
ヘルスチェック項目としては以下の3種類があります。
- httpGet
- exec
- コマンドの終了コードが0なら成功
- tcpSocket
- 特定のPortへのTCP接続、Portが開いていれば成功
ConfigMap, Secret
k8sにおける依存性として以下のようなものがあり、コンテナの実行環境によって変更したいものがあります。
それをかく環境に向けてコンテナをビルドするのは非効率です。 そのためにk8sにはConfigMapというものが存在します。
基本的にPod作成時に環境変数を設定するときは下の図のようにします。

ConfigMapを使用したときのマニフェストファイルは下の図のようになります。

これらの図は同義でENVという環境変数に"HELLO WORLD"という値が設定されます。
Secret
Secretとは暗号化されたConfigMapです。
ConfigMapと同じように作成しますが作成した後は環境変数などのkeyが見えなくなります。
暗号化といってもBase64でエンコードされているだけですが。その丸見えの暗号化で重要なのは、誰にでも見えていい情報と見る人が限定されている情報を区別することにあります。
今回は深く紹介しませんがk8sにはRBAC (RoleBasedAccessControl)という機能があり、だれがどのリソースを閲覧/作成/削除/更新ができるのかを制御することができます。 この機能を用いてSecretを閲覧できる人を制限します。
Kubernetesにおけるコンテナのスケール
k8sに備わっているスケール機能には以下のようなものがあります。
Deployment
DeploymentについてはServiceでも少し触れましたが、Podを複数起動し決められたPodが起動していることを担保してくれます。
マニフェストファイルはこんな感じです。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deploy
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:stable-alpine
このDeploymentによって同等のnginxを3台起動し、別でnginxというセレクタのサービスを起動しDeploymentによって監視します。
HPA (Horizontal Pod Autoscaler)
k8sではPodにリソース(CPU/メモリ)を指定し、必要以上のリソースを使ったり、最低限必要なリソースを確保したりできます。(pod.spec.resources.requests/.limit以下に書き込む)
spec:
containers:
- name: nginx
image: nginx:stable-alpine
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 500m
memory: 500Mi
※1 vCPU = 940 mCPU
requestsを満たせないNodeにはPodが配置されません。また、limit.memoryに指定した量以上のmemoryを消費するとPodが強制的にkillされます。
HPAはPodのCPU使用量が、resources.requestsに指定した量に対して、望む割合を満たすようにPodを水平スケールさせます。そのPodに流れ込むトラフィックが限界値を超えれば勝手にスケールし、収まればkillされていくわけですね。
この記事で触れていないKubernetesのキーワード
・Ingress(アプリケーションロードバランサ)
・StatefulSet
・RBAC
・PodDisruptionBudget
・Job / CronJob
・nodeAffinity / Taint, Torelation
・Daemonset
・LimitRange
・ServiceAccount
また、 下記コマンドにて出力される内容を一から網羅すればk8sマスターになれます。
$ kubectl api-service
資格について
Kubernetes Application Developer
Kubernetesクラスタ上で各リソースの操作とトラブルシューティングをする技術
試験官が問題を出し解決する過程を監視する
Certified Kubernetes Application Developer (CKAD) Program
Kubernetes Administrator
Kubernetesクラスタを管理する技術
Certified Kubernetes Administrator (CKA) Program
少々長くなってしまいましたが、この辺で終わろうかと思います。
次の記事ではハンズオン、やっていこうと思います!
それでは